
In this article, we look at how machine learning is boosting compiler autotuning. We provide a comprehensive overview of traditional compiler optimization techniques and their limitations, highlighting the need for more adaptive and data-driven approaches. Afterward, we dive deeper into various ML methods, including supervised and reinforcement learning, and show how they enable compilers to learn, adapt, and make intelligent optimization decisions. Key takeaways include the potential for ML to significantly enhance software performance and efficiency, as well as the challenges and opportunities presented by this emerging field.
Index Terms — Machine Learning, Compilers, Code Optimization, Performance Modeling, Adaptive Compilation, Automated Code Generation, Intelligent Systems, Software Development, Compiler Autotuning, Reinforcement Learning, Supervised Learning.
Introduction
The quest for faster and more efficient code execution is a key objective in software development’s ever-evolving landscape.
For many years, compilers have used hand-crafted heuristics and static analysis techniques to achieve excellent results when optimizing code. However, the increasing complexity of modern software, coupled with the diversity of hardware architectures, has exposed the limitations of these traditional methods.
Here comes machine learning (ML), a transformative force that is revolutionizing various domains, and compiler autotuning is no exception. ML is enabling compilers to overcome their traditional limitations by leveraging the power of data-driven insights and adaptive algorithms.
Join us as we unravel the potential of machine learning to reshape the landscape of compiler technology and pave the way for a new era of software performance and efficiency. 🚀
Traditional Compilers and Optimization
What is a Compiler?
🔳 At the heart of software development lies the compiler, an indispensable tool that bridges the gap between human-readable code and machine-executable instructions.
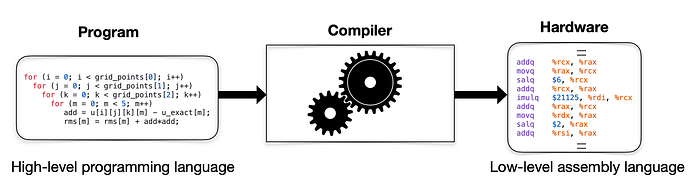
🔳 In essence, a compiler acts as a translator, converting source code written in a high-level programming language (such as C++, Java, or Python) into a low-level language that the computer’s processor can understand and execute directly.
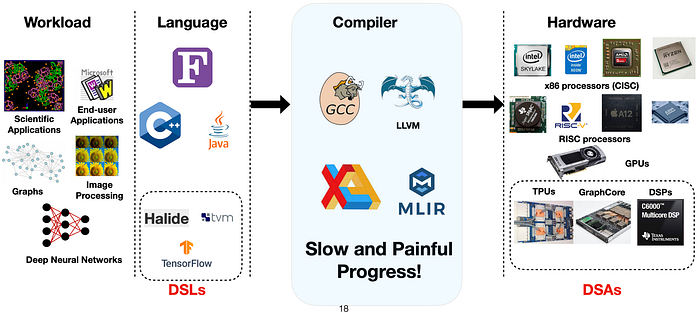
🔳 This translation process is far from trivial; it involves a series of intricate phases that meticulously analyze, transform, and optimize the code to ensure its correctness and efficiency.
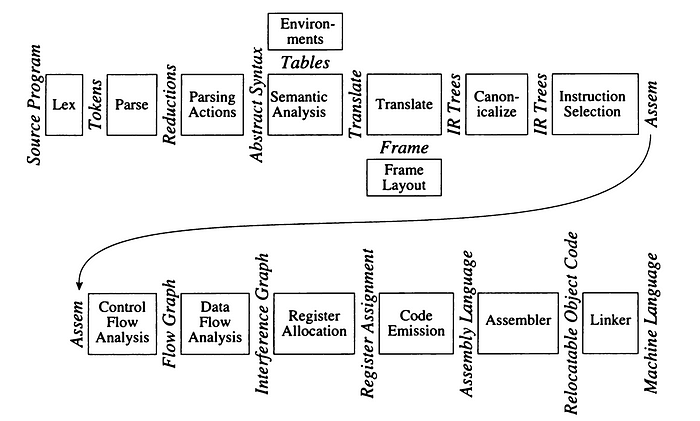
🔳 The compilation process is typically divided into three main stages: Frontend, Optimization (Middle End) and Backend:
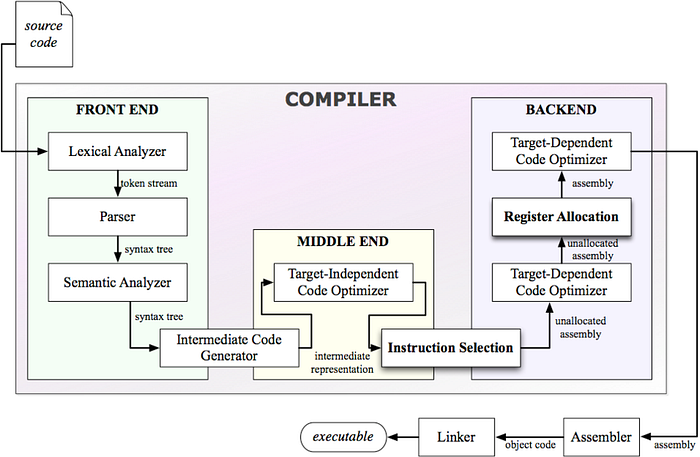
1️⃣ Frontend: This stage is responsible for analyzing and understanding the source code:
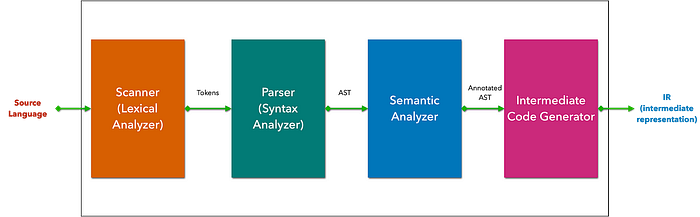
🔸 Lexical Analysis: The compiler begins by breaking down the source code into a stream of tokens, which are the fundamental building blocks of the language. This phase identifies keywords, identifiers, literals, operators, and punctuation symbols.

🔸 Syntax Analysis (Parsing): The stream of tokens is then parsed to determine the grammatical structure of the code. This involves checking if the code adheres to the language’s syntax rules and constructing a parse tree or abstract syntax tree (AST) that represents the code’s hierarchical structure.
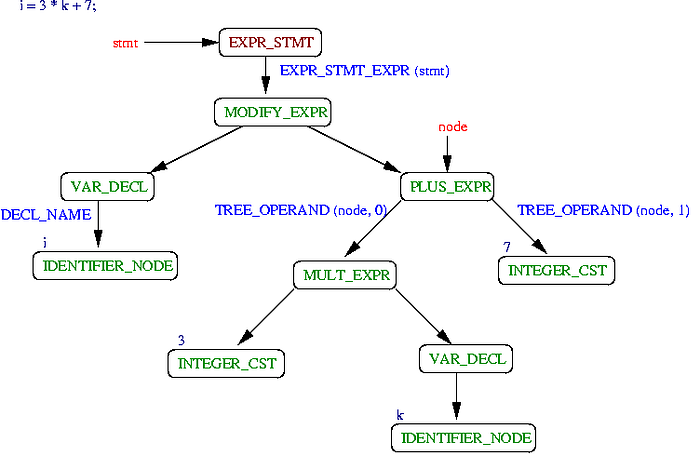
🔸 Semantic Analysis: In this phase, the compiler delves deeper into the meaning of the code, verifying type compatibility, checking for undeclared variables, and ensuring that operations are performed on appropriate data types. It also resolves references to variables and functions.
🔸 Intermediate Code Generation: The compiler translates the AST into an intermediate representation (IR), a platform-independent form of the code. This IR serves as a bridge between the high-level source code and the target machine code.
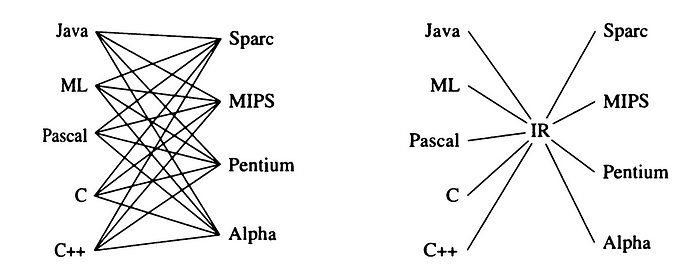
2️⃣ Optimization (Middle End): This stage aims to improve the efficiency of the code by applying various transformations to the IR:
🔸 Target-Independent Code Optimizer: Performs optimizations that are not specific to any particular target machine architecture.
🔸 Target-Dependent Code Optimizer: Applies optimizations tailored to the specific target architecture.
3️⃣ Backend: This stage is responsible for generating machine code for the target architecture:
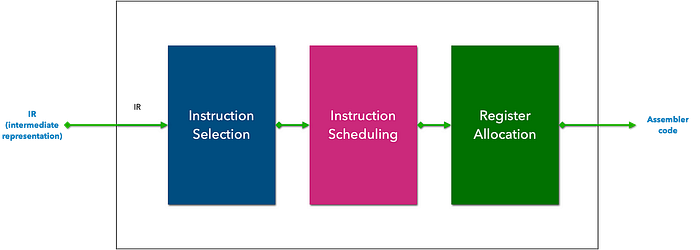
🔸 Instruction Selection: In this stage, the compiler chooses the appropriate machine instructions from the target architecture’s instruction set to implement the operations specified in the IR.

🔸 Instruction Scheduling: This phase determines the order in which the selected instructions will be executed. The goal is to optimize the instruction sequence for performance, considering factors like pipeline dependencies, resource availability, and latency.

🔸 Register allocation: is a crucial step in compilation that involves assigning a limited number of physical registers to variables in a program. Two primary techniques are used: allocation by graph coloring and allocation by linear scan.
